Since we know no theoretical reason why the distribution of lifetimes should fit the uniform-log model we propose, it is natural to ask whether the techniques presented here are applicable to other environments.
To answer this question, we obtained data from the IBM SP2 at the Cornell Theory Center [9], including the submission times, execution times and cluster sizes for 50862 jobs submitted during the six-month interval from June 18 to December 2, 1995.
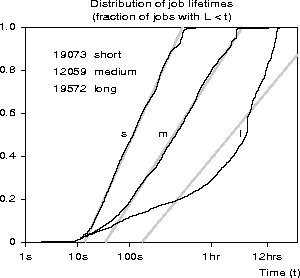
Figure 7: The distribution of lifetimes for batch jobs submitted to the IBM SP2
at CTC, broken down according to the queue to which they were
submitted.
We divided these jobs into three groups -- short, medium and long --
according to the name of the queue to which they were submitted.
Figure 7 shows the distribution of lifetimes for these
groups. As with the jobs on the Paragon at SDSC, the uniform-log model
fits well for the short and medium groups, and not as well for the
long group. Nevertheless, the ![]() values for these fits are
somewhat better across the board than those from the Paragon data:
values for these fits are
somewhat better across the board than those from the Paragon data:
Table 4

The relationships among the three curves are not the same as among the jobs from the Paragon. On the Paragon the estimated lines were nearly parallel; only the intercept varied from group to group. On the SP2, the lines have nearly the same intercept; it is their slopes that vary. This observation suggests that these distributions vary from environment to environment, but that the proposed model is able to span this range of behavior.
Next, we submitted the trace data from the SP2 to the same simulator we used for the Paragon data. The only change we made to the simulator was to plug in the estimated parameters from Table 4.
Of the 50862 jobs in the trace, 4026 received predictions from Predictor A and 4156 received predictions from Predictor B. The performance of the two predictors follows the same pattern as with the SDSC data -- Predictor A is best for small values of n'; Predictor B for large. The CC for the combined predictor is 0.72, which is a significantly better than the predictions for the SDSC data (CC = 0.65).
One reason for this improvement is that the SP2 is a bigger machine (430 nodes vs. 368 on the Paragon), and the average cluster size of jobs tended to be smaller (9.2 vs. 25.2 on the Paragon). Thus, there tend to be more jobs in the system at any given time. Since our predictions are based on the aggregate behavior of many jobs, we expect them to improve as the number of jobs in the system increases. Another reason for the improvement is that users at CTC appear to be providing better run time estimates than users at SDSC: there is less overlap between the distributions from different queues, and the distribution of lifetimes for long jobs is less bimodal.