If I have a tumor that I’ve been told has a malignancy rate of 2% per year, does that compound? So after 5 years there’s a 10% chance it will turn malignant?
This turns out to be an interesting question, because the answer depends on what that 2% means. If we know that it’s the same for everyone, and it doesn’t vary over time, computing the compounded probability after 5 years is a relatively simple.
But if that 2% is an average across people with different probabilities, the computation is a little more complicated – and the answer turns out to be substantially different, so this is not a negligible effect.
To demonstrate both computations, I’ll assume that the probability for a given patient doesn’t change over time. This assumption is consistent with the multistage model of carcinogenesis, which posits that normal cells become cancerous through a series of mutations, where the probability of any of those mutations is constant over time.
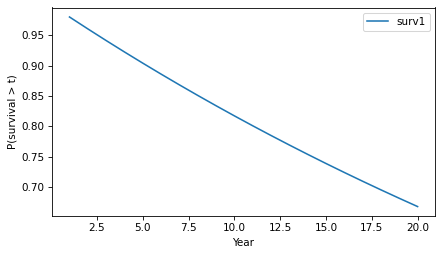
Let’s start with the simpler calculation, where the probability that a tumor progresses to malignancy is known to be 2% per year and constant. In that case, we can answer OP’s question by making a constant hazard function and using it to compute a survival function.
empiricaldist provides a Hazard object that represents a hazard function. Here’s one where the hazard is 2% per year for 20 years.
from empiricaldist import Hazard
p = 0.02
ts = np.arange(1, 21)
hazard = Hazard(p, ts, name='hazard1')
The probability that a tumor survives a given number of years without progressing is the cumulative product of the complements of the hazard, which we can compute like this.
p_surv = (1 - hazard).cumprod()
Hazard provides a make_surv method that does this computation and returns a Surv object that represents the corresponding survival function.
The y-axis shows the probability that a tumor “survives” for more than a given number of years without progressing. The probability of survival past Year 1 is 98%, as you might expect.
surv.head()
probs
1
0.980000
2
0.960400
3
0.941192
And the probability of going more than 10 years without progressing is about 82%.
surv(10)
array(0.81707281)
Because of the way the probabilities compound, the survival function drops off with decreasing slope, even though the hazard is constant.
Knowledge is Power
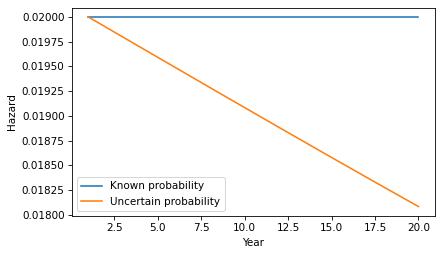
Now let’s add a little more realism to the model. Suppose that in the observed population the average rate of progression is 2% per year, but it varies from one person to another. As an example, suppose the actual rate is 1% for half the population and 3% for the other half. And for a given patient, suppose we don’t know initially which group they are in.
[UPDATE: If you read an earlier version of this article, there was an error in this section – I had the likelihood ratio wrong and it had a substantial effect on the results.]
As in the previous example, the probability that the tumor goes a year without progressing is 98%. However, at the end of that year, if it has not progressed, we have evidence in favor of the hypothesis that the patient is in the low-progression group. Specifically, the likelihood ratio is 99/97 in favor of that hypothesis.
Now we can apply Bayes’s rule in odds form. Since the prior odds were 1:1 and the likelihood ratio is 99/97, the posterior odds are 99:97 – so after one year we now believe the probability is 50.5% that the patient is in the low-progression group.
p_low = 99 / (99 + 97)
p_low
0.5051020408163265
In that case we can update the probability that the tumor progresses in the second year:
p1 = 0.01
p2 = 0.03
p_low * p1 + (1-p_low) * p2
0.019897959183673472
If the tumor survives a year without progressing, the probability it will progress in the second year is 1.99%, slightly less than the initial estimate of 2%. Note that this change is due to evidence that the patient is in the low progression group. It does not assume that anything has changed in the world – only that we have more information about which world we’re in.
If the tumor lasts another year without progressing, we would do the same update again. The following loop repeats this computation for 20 years.
odds = 1
ratio = 99/97
res = []
for year in hazard.index:
p_low = odds / (odds + 1)
haz = p_low * p1 + (1-p_low) * p2
res.append((p_low, haz))
odds *= ratio
Each year, the probability increases that the patient is in the low-progression group, so the probability of progressing in the next year is a little lower.
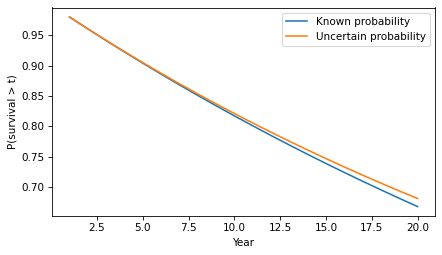
Here’s what the corresponding survival function looks like.
The difference in survival is small, but it accumulates over time. For example, the probability of going more than 20 years without progression increases from 67% to 68%.
surv(20), surv2(20)
(array(0.66760797), array(0.68085064))
In this example, there are only two groups with different probabilities of progression. But we would see the same effect in a more realistic model with a range of probabilities. As time passes without progression, it becomes more likely that the patient is in a low-progression group, so their hazard during the next period is lower. The more variability there is in the probability of progression, the stronger this effect.
Discussion
This example demonstrates a subtle point about a distribution of probabilities. To explain it, let’s consider a more abstract scenario. Suppose you have two coin-flipping devices:
One of them is known to flips head and tails with equal probability.
The other is known to be miscalibrated so it flips heads with either 60% probability or 40% probability – and we don’t know which, but they are equally likely.
If we use the first device, the probability of heads is 50%. If we use the second device, the probability of heads is 50%. So it might seem like there is no difference between them – and more generally, it might seem like we can always collapse a distribution of probabilities down to a single probability.
But that’s not true, as we can demonstrate by running the coin-flippers twice. For the first, the probability of two heads is 25%. For the second, it’s either 36% or 16% with equal probability – so the total probability is 26%.
p1, p2 = 0.6, 0.4
np.mean([p1**2, p2**2])
0.26
In general, there’s a difference between a scenario where a probability is known precisely and a scenario where there is uncertainty about the probability.
Our World in Data recently announced that they are providing APIs to access their data. Coincidentally, I am using one of their datasets in my workshop on time series analysis at PyData Global 2024. So I took this opportunity to update my example using the new API – this notebook shows what I learned.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Air Temperature
In the chapter on time series analysis, in an exercise on seasonal decomposition, I use monthly average surface temperatures in the United States, from a dataset from Our World in Data that includes “temperature [in Celsius] of the air measured 2 meters above the ground, encompassing land, sea, and in-land water surfaces,” for most countries in the world from 1941 to 2024.
The following cells download and display the metadata that describes the dataset.
import requests
url = ( "https://ourworldindata.org/grapher/" "average-monthly-surface-temperature.metadata.json" ) query_params = { "v": "1", "csvType": "full", "useColumnShortNames": "true" } headers = {'User-Agent': 'Our World In Data data fetch/1.0'}
The result is a nested dictionary. Here are the top-level keys.
metadata.keys()
dict_keys(['chart', 'columns', 'dateDownloaded'])
Here’s the chart-level documentation.
from pprint import pprint
pprint(metadata['chart'])
{'citation': 'Contains modified Copernicus Climate Change Service information '
'(2019)',
'originalChartUrl': 'https://ourworldindata.org/grapher/average-monthly-surface-temperature?v=1&csvType=full&useColumnShortNames=true',
'selection': ['World'],
'subtitle': 'The temperature of the air measured 2 meters above the ground, '
'encompassing land, sea, and in-land water surfaces.',
'title': 'Average monthly surface temperature'}
And here’s the documentation of the column we’ll use.
pprint(metadata['columns']['temperature_2m'])
{'citationLong': 'Contains modified Copernicus Climate Change Service '
'information (2019) – with major processing by Our World in '
'Data. “Annual average” [dataset]. Contains modified '
'Copernicus Climate Change Service information, “ERA5 monthly '
'averaged data on single levels from 1940 to present 2” '
'[original data].',
'citationShort': 'Contains modified Copernicus Climate Change Service '
'information (2019) – with major processing by Our World in '
'Data',
'descriptionKey': [],
'descriptionProcessing': '- Temperature measured in kelvin was converted to '
'degrees Celsius (°C) by subtracting 273.15.\n'
'\n'
'- Initially, the temperature dataset is provided '
'with specific coordinates in terms of longitude and '
'latitude. To tailor this data to each country, we '
'utilize geographical boundaries as defined by the '
'World Bank. The method involves trimming the global '
'temperature dataset to match the exact geographical '
'shape of each country. To correct for potential '
"distortions caused by the Earth's curvature on a "
'flat map, we apply a latitude-based weighting. This '
'step is essential for maintaining accuracy, '
'especially in high-latitude regions where '
'distortion is more pronounced. The result of this '
'process is a latitude-weighted average temperature '
'for each nation.\n'
'\n'
"- It's important to note, however, that due to the "
'resolution constraints of the Copernicus dataset, '
'this methodology might not be as effective for '
'countries with very small landmasses. In these '
'cases, the process may not yield reliable data.\n'
'\n'
'- The derived 2-meter temperature readings for each '
'country are calculated based on administrative '
'borders, encompassing all land surface types within '
'these defined areas. As a result, temperatures over '
'oceans and seas are not included in these averages, '
'focusing the data primarily on terrestrial '
'environments.\n'
'\n'
'- Global temperature averages and anomalies are '
'calculated over all land and ocean surfaces.',
'descriptionShort': 'The temperature of the air measured 2 meters above the '
'ground, encompassing land, sea, and in-land water '
'surfaces. The 2024 data is incomplete and was last '
'updated 13 October 2024.',
'fullMetadata': 'https://api.ourworldindata.org/v1/indicators/819532.metadata.json',
'lastUpdated': '2023-12-20',
'owidVariableId': 819532,
'shortName': 'temperature_2m',
'shortUnit': '°C',
'timespan': '1940-2024',
'titleLong': 'Annual average',
'titleShort': 'Annual average',
'type': 'Numeric',
'unit': '°C'}
The following cells download the data for the United States – to see data from another country, change country_code to almost any three-letter ISO 3166 country codes.
country_code = 'USA' # replace this with other three-letter country codes base_url = ( "https://ourworldindata.org/grapher/" "average-monthly-surface-temperature.csv" )
In general, you can find out which query parameters are supported by exploring the dataset online and pressing the download icon, which displays a URL with query parameters corresponding to the filters you selected by interacting with the chart.
temp_df.head()
Entity
Code
year
Day
temperature_2m
temperature_2m.1
0
United States
USA
1941
1941-12-15
-1.878019
8.016244
1
United States
USA
1942
1942-01-15
-4.776551
7.848984
2
United States
USA
1942
1942-02-15
-3.870868
7.848984
3
United States
USA
1942
1942-03-15
0.097811
7.848984
4
United States
USA
1942
1942-04-15
7.537291
7.848984
The resulting DataFrame includes the column that’s documented in the metadata, temperature_2m, and an additional undocumented column, which might be an annual average.
temp_series.plot(label=country_code)
plt.ylabel("Surface temperature (℃)");
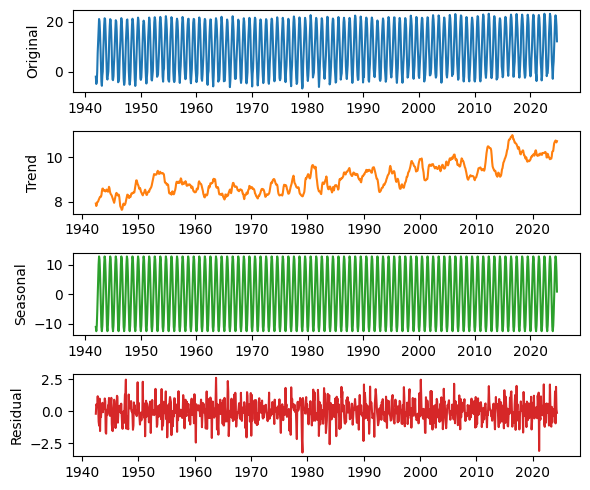
Not surprisingly, there is a strong seasonal pattern. We can use seasonal_decompose from StatsModels to identify a long-term trend, a seasonal component, and a residual.
from statsmodels.tsa.seasonal import seasonal_decompose
decomposition = seasonal_decompose(temp_series, model="additive", period=12)
We’ll use the following function to plot the results.
Recently I heard the word “chartist” for the first time in my life (that I recall). And then later the same day, I heard it again. So that raises two questions:
What are the chances of going 57 years without hearing a word, and then hearing it twice in one day?
Also, what’s a chartist?
To answer the second question first, it’s someone who supported chartism, which was “a working-class movement for political reform in the United Kingdom that erupted from 1838 to 1857”, quoth Wikipedia. The name comes from the People’s Charter of 1838, which called for voting rights for unpropertied men, among other reforms.
To answer the first question, we’ll do some Bayesian statistics. My solution is based on a model that’s not very realistic, so we should not take the result too seriously, but it demonstrates some interesting methods, I think. And as you’ll see, there is a connection to Zipf’s law, which I wrote about last week.
Since last week’s post was at the beginner level, I should warn you that this one is more advanced – in rapid succession, it involves the beta distribution, the t distribution, the negative binomial, and the binomial.
This post is based on Think Bayes 2e, which is available from Bookshop.org and Amazon.
If you don’t hear a word for more than 50 years, that suggests it is not a common word. We can use Bayes’s theorem to quantify this intuition. First we’ll compute the posterior distribution of the word’s frequency, then the posterior predictive distribution of hearing it again within a day.
Because we have only one piece of data – the time until first appearance – we’ll need a good prior distribution. Which means we’ll need a large, good quality sample of English text. For that, I’ll use a free sample of the COCA dataset from CorpusData.org. The following cells download and read the data.
import zipfile
def generate_lines(zip_path="coca-samples-text.zip"):
with zipfile.ZipFile(zip_path, "r") as zip_file:
file_list = zip_file.namelist()
for file_name in file_list:
with zip_file.open(file_name) as file:
lines = file.readlines()
for line in lines:
yield (line.decode("utf-8"))
We’ll use a Counter to count the number of times each word appears.
import re
from collections import Counter
pattern = r"[ /\n]+|--"
counter = Counter()
for line in generate_lines():
words = re.split(pattern, line)[1:]
counter.update(word.lower() for word in words if word)
The dataset includes about 188,000 unique strings, but not all of them are what we would consider words.
len(counter), counter.total()
(188086, 11503819)
To narrow it down, I’ll remove anything that starts or ends with a non-alphabetical character – so hyphens and apostrophes are allowed in the middle of a word.
for s in list(counter.keys()):
if not s[0].isalpha() or not s[-1].isalpha():
del counter[s]
This filter reduces the number of unique words to about 151,000.
Of the 50 most common words, all of them have one syllable except number 38. Before you look at the list, can you guess the most common two-syllable word? Here’s a theory about why common words are short.
for i, (word, freq) in enumerate(counter.most_common(50)):
print(f'{i+1}\t{word}\t{freq}')
1 the 461991
2 to 237929
3 and 231459
4 of 217363
5 a 203302
6 in 153323
7 i 137931
8 that 123818
9 you 109635
10 it 103712
11 is 93996
12 for 78755
13 on 64869
14 was 64388
15 with 59724
16 he 57684
17 this 51879
18 as 51202
19 n't 49291
20 we 47694
21 are 47192
22 have 46963
23 be 46563
24 not 43872
25 but 42434
26 they 42411
27 at 42017
28 do 41568
29 what 35637
30 from 34557
31 his 33578
32 by 32583
33 or 32146
34 she 29945
35 all 29391
36 my 29390
37 an 28580
38 about 27804
39 there 27291
40 so 27081
41 her 26363
42 one 26022
43 had 25656
44 if 25373
45 your 24641
46 me 24551
47 who 23500
48 can 23311
49 their 23221
50 out 22902
There are about 72,000 words that only appear once in the corpus, technically known as hapax legomena.
singletons = [word for (word, freq) in counter.items() if freq == 1]
len(singletons), len(singletons) / counter.total() * 100
(72159, 0.811715228893143)
Here’s a random selection of them. Many are proper names, typos, or other non-words, but some are legitimate but rare words.
Zipf’s law suggest that the result should be a straight line with slope close to -1. It’s not exactly a straight line, but it’s close, and the slope is about -1.1.
run = np.log10(ranks[-1]) - np.log10(ranks[0])
run
5.180166032638616
rise / run
-1.0935235433575892
The Zipf plot is a well-known visual representation of the distribution of frequencies, but for the current problem, we’ll switch to a different representation.
Tail Distribution
Given the number of times each word appear in the corpus, we can compute the rates, which is the number of times we expect each word to appear in a sample of a given size, and the inverse rates, which are the number of words we need to see before we expect a given word to appear.
We will find it most convenient to work with the distribution of inverse rates on a log scale. The first step is to use the observed frequencies to estimate word rates – we’ll estimate the rate at which each word would appear in a random sample.
We’ll do that by creating a beta distribution that represents the posterior distribution of word rates, given the observed frequencies (see this section of Think Bayes) – and then drawing a random sample from the posterior. So words that have the same frequency will not generally have the same inferred rate.
Now we can compute the inverse rates, which are the number of words we have to sample before we expect to see each word once.
inverse_rates = 1 / inferred_rates
And here are their magnitudes, expressed as logarithms base 10.
mags = np.log10(inverse_rates)
To represent the distribution of these magnitudes, we’ll use a Surv object, which represents survival functions, but we’ll use a variation of the survival function which is the probability that a randomly-chosen value is greater than or equal to a given quantity. The following function computes this version of a survival function, which is called a tail probability.
from empiricaldist import Surv
def make_surv(seq):
"""Make a non-standard survival function, P(X>=x)"""
pmf = Pmf.from_seq(seq)
surv = pmf.make_surv() + pmf
# correct for numerical error
surv.iloc[0] = 1
return Surv(surv)
Here’s how we make the survival function.
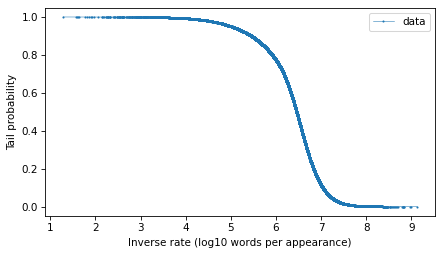
surv = make_surv(mags)
And here’s what it looks like.
options = dict(marker=".", ms=2, lw=0.5, label="data")
surv.plot(**options)
decorate(xlabel="Inverse rate (log10 words per appearance)", ylabel="Tail probability")
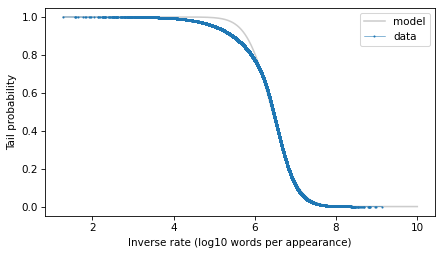
The tail distribution has the sigmoid shape that is characteristic of normal distributions and t distributions, although it is notably asymmetric.
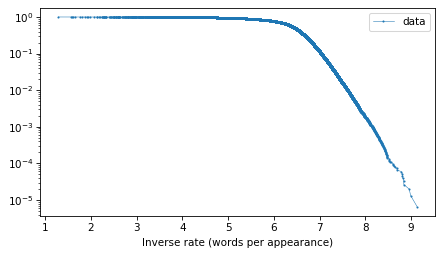
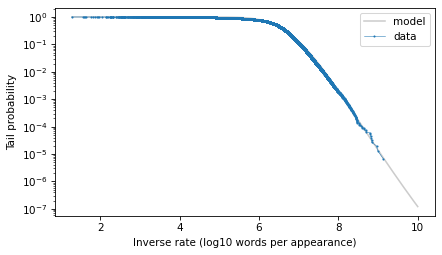
And here’s what the tail probabilities look like on a log-y scale.
surv.plot(**options)
decorate(xlabel="Inverse rate (words per appearance)", yscale="log")
If this distribution were normal, we would expect this curve to drop off with increasing slope. But for the words with the lowest frequencies – that is, the highest inverse rates – it is almost a straight line. And that suggests that a
distribution might be a good model for this data.
Fitting a Model
To estimate the frequency of rare words, we will need to model the tail behavior of this distribution and extrapolate it beyond the data. So let’s fit a t distribution and see how it looks. I’ll use code from Chapter 8 of Probably Overthinking It, which is all about these long-tailed distributions.
The following function makes a Surv object that represents a t distribution with the given parameters.
from scipy.stats import t as t_dist
def truncated_t_sf(qs, df, mu, sigma):
"""Makes Surv object for a t distribution.
Truncated on the left, assuming all values are greater than min(qs)
"""
ps = t_dist.sf(qs, df, mu, sigma)
surv_model = Surv(ps / ps[0], qs)
return surv_model
If we are given the df parameter, we can use the following function to find the values of mu and sigma that best fit the data, focusing on the central part of the distribution.
from scipy.optimize import least_squares
def fit_truncated_t(df, surv):
"""Given df, find the best values of mu and sigma."""
low, high = surv.qs.min(), surv.qs.max()
qs_model = np.linspace(low, high, 2000)
ps = np.linspace(0.1, 0.8, 20)
qs = surv.inverse(ps)
def error_func_t(params, df, surv):
mu, sigma = params
surv_model = truncated_t_sf(qs_model, df, mu, sigma)
error = surv(qs) - surv_model(qs)
return error
pmf = surv.make_pmf()
pmf.normalize()
params = pmf.mean(), pmf.std()
res = least_squares(error_func_t, x0=params, args=(df, surv), xtol=1e-3)
assert res.success
return res.x
But since we are not given df, we can use the following function to search for the value that best fits the tail of the distribution.
from scipy.optimize import minimize
def minimize_df(df0, surv, bounds=[(1, 1e3)], ps=None): low, high = surv.qs.min(), surv.qs.max() qs_model = np.linspace(low, high * 1.2, 2000)
if ps is None: t = surv.ps[0], surv.ps[-5] low, high = np.log10(t) ps = np.logspace(low, high, 30, endpoint=False)
surv_model.plot(color="gray", alpha=0.4, label="model")
surv.plot(**options)
decorate(xlabel="Inverse rate (log10 words per appearance)", ylabel="Tail probability")
With the y-axis on a linear scale, we can see that the model fits the data reasonably well, except for a range between 5 and 6 – that is for words that appear about 1 time in a million.
Here’s what the model looks like on a log-y scale.
surv_model.plot(color="gray", alpha=0.4, label="model")
surv.plot(**options)
decorate(
xlabel="Inverse rate (log10 words per appearance)",
ylabel="Tail probability",
yscale="log",
)
The model fits the data well in the extreme tail, which is exactly where we need it. And we can use the model to extrapolate a little beyond the data, to make sure we cover the range that will turn out to be likely in the scenario where we hear a word for this first time after 50 years.
The Update
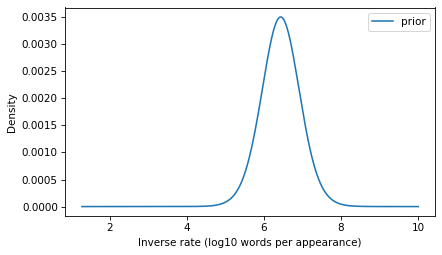
The model we’ve developed is the distribution of inverse rates for the words that appear in the corpus and, by extrapolation, for additional rare words that didn’t appear in the corpus. This distribution will be the prior for the Bayesian update. We just have to convert it from a survival function to a PMF (remembering that these are equivalent representations of the same distribution).
prior = surv_model.make_pmf()
prior.plot(label="prior")
decorate(
xlabel="Inverse rate (log10 words per appearance)",
ylabel="Density",
)
To compute the likelihood of the observation, we have to transform the inverse rates to probabilities.
ps = 1 / np.power(10, prior.qs)
Now suppose that in a given day, you read or hear 10,000 words in a context where you would notice if you heard a word for the first time. Here’s the number of words you would hear in 50 years.
words_per_day = 10_000
days = 50 * 365
k = days * words_per_day
k
182500000
Now, what’s the probability that you fail to encounter a word in k attempts and then encounter it on the next attempt? We can answer that with the negative binomial distribution, which computes the probability of getting the nth success after k failures, for a given probability – or in this case, for a sequence of possible probabilities.
from scipy.stats import nbinom
n = 1
likelihood = nbinom.pmf(k, n, ps)
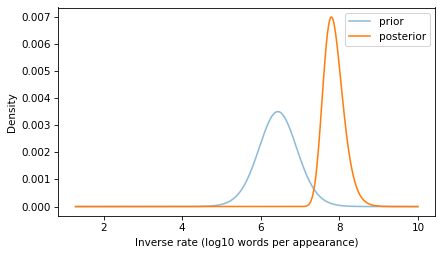
With this likelihood and the prior, we can compute the posterior distribution in the usual way.
prior.plot(alpha=0.5, label="prior")
posterior.plot(label="posterior")
decorate(
xlabel="Inverse rate (log10 words per appearance)",
ylabel="Density",
)
If you go 50 years without hearing a word, that suggests that it is a rare word, and the posterior distribution reflects that logic.
The posterior distribution represents a range of possible values for the inverse rate of the word you heard. Now we can use it to answer the question we started with: what is the probability of hearing the same word again on the same day – that is, within the next 10,000 words you hear?
To answer that, we can use the survival function of the binomial distribution to compute the probability of more than 0 successes in the next n_pred attempts. We’ll compute this probability for each of the ps that correspond to the inverse rates in the posterior.
And we can use the probabilities in the posterior to compute the expected value – by the law of total probability, the result is the probability of hearing the same word again within a day.
p = np.sum(posterior * ps_pred)
p, 1 / p
(0.00016019406802217392, 6242.42840166579)
The result is about 1 in 6000.
With all of the assumptions we made in this calculation, there’s no reason to be more precise than that. And as I mentioned at the beginning, we should probably not take this conclusion too seriously. For one thing, it’s likely that my experience is an example of the frequency illusion, which is “a cognitive bias in which a person notices a specific concept, word, or product more frequently after recently becoming aware of it.” Also, if you hear a word for the first time after 50 years, there’s a good chance the word is having a moment, which greatly increases the chance you’ll hear it again. I can’t think of why chartism might be in the news at the moment, but maybe this post will go viral and make it happen.
This is the second is a series of excerpts from Elements of Data Science which available from Lulu.com and online booksellers. It’s from Chapter 8, which is about representing distribution using PMFs and CDFs. This section explains why I think CDFs are often better for plotting and comparing distributions.You can read the complete chapter here, or run the Jupyter notebook on Colab.
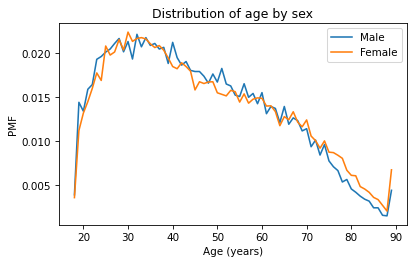
So far we’ve seen two ways to represent distributions, PMFs and CDFs. Now we’ll use PMFs and CDFs to compare distributions, and we’ll see the pros and cons of each. One way to compare distributions is to plot multiple PMFs on the same axes. For example, suppose we want to compare the distribution of age for male and female respondents. First we’ll create a Boolean Series that’s true for male respondents and another that’s true for female respondents.
male = (gss['sex'] == 1)
female = (gss['sex'] == 2)
We can use these Series to select ages for male and female respondents.
male_age = age[male]
female_age = age[female]
And plot a PMF for each.
pmf_male_age = Pmf.from_seq(male_age)
pmf_male_age.plot(label='Male')
pmf_female_age = Pmf.from_seq(female_age)
pmf_female_age.plot(label='Female')
plt.xlabel('Age (years)')
plt.ylabel('PMF')
plt.title('Distribution of age by sex')
plt.legend();
A plot as variable as this is often described as noisy. If we ignore the noise, it looks like the PMF is higher for men between ages 40 and 50, and higher for women between ages 70 and 80. But both of those differences might be due to randomness.
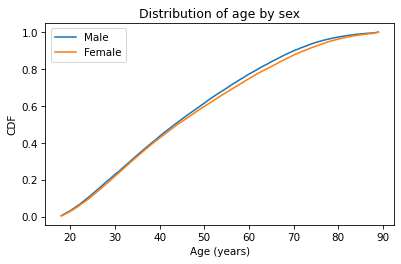
Now let’s do the same thing with CDFs – everything is the same except we replace Pmf with Cdf.
cdf_male_age = Cdf.from_seq(male_age)
cdf_male_age.plot(label='Male')
cdf_female_age = Cdf.from_seq(female_age)
cdf_female_age.plot(label='Female')
plt.xlabel('Age (years)')
plt.ylabel('CDF')
plt.title('Distribution of age by sex')
plt.legend();
Because CDFs smooth out randomness, they provide a better view of real differences between distributions. In this case, the lines are close together until age 40 – after that, the CDF is higher for men than women.
So what does that mean? One way to interpret the difference is that the fraction of men below a given age is generally more than the fraction of women below the same age. For example, about 77% of men are 60 or less, compared to 75% of women.
cdf_male_age(60), cdf_female_age(60)
(array(0.7721998), array(0.7474241))
Going the other way, we could also compare percentiles. For example, the median age woman is older than the median age man, by about one year.
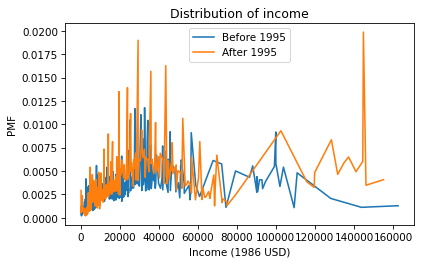
As another example, let’s look at household income and compare the distribution before and after 1995 (I chose 1995 because it’s roughly the midpoint of the survey). We’ll make two Boolean Series objects to select respondents interviewed before and after 1995.
There are a lot of unique values in this distribution, and none of them appear very often. As a result, the PMF is so noisy and we can’t really see the shape of the distribution. It’s also hard to compare the distributions. It looks like there are more people with high incomes after 1995, but it’s hard to tell. We can get a clearer picture with a CDF.
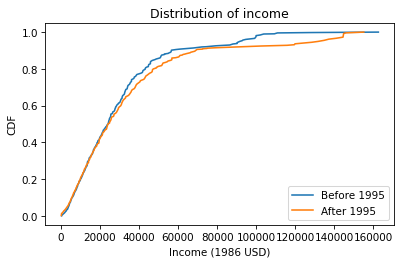
Below $30,000 the CDFs are almost identical; above that, we can see that the post-1995 distribution is shifted to the right. In other words, the fraction of people with high incomes is about the same, but the income of high earners has increased.
In general, I recommend CDFs for exploratory analysis. They give you a clear view of the distribution, without too much noise, and they are good for comparing distributions.
Elements of Data Science is in print now, available from Lulu.com and online booksellers. To celebrate, I’ll post some excerpts here, starting with one of my favorite examples, Zipf’s Law. It’s from Chapter 6, which is about plotting data, and it uses Python dictionaries, which are covered in the previous chapter. You can read the complete chapter here, or run the Jupyter notebook on Colab.
In almost any book, in almost any language, if you count the number of unique words and the number of times each word appears, you will find a remarkable pattern: the most common word appears twice as often as the second most common – at least approximately – three times as often as the third most common, and so on.
In general, if we sort the words in descending order of frequency, there is an inverse relationship between the rank of the words – first, second, third, etc. – and the number of times they appear. This observation was most famously made by George Kingsley Zipf, so it is called Zipf’s law.
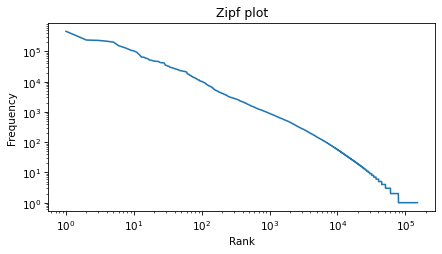
To see if this law holds for the words in War and Peace, we’ll make a Zipf plot, which shows:
The frequency of each word on the y-axis, and
The rank of each word on the x-axis, starting from 1.
In the previous chapter, we looped through the book and made a string that contains all punctuation characters. Here are the results, which we will need again.
all_punctuation = ',.-:[#]*/“’—‘!?”;()%@'
The following program reads through the book and makes a dictionary that maps from each word to the number of times it appears.
fp = open('2600-0.txt')
for line in fp:
if line.startswith('***'):
break
unique_words = {}
for line in fp:
if line.startswith('***'):
break
for word in line.split():
word = word.lower()
word = word.strip(all_punctuation)
if word in unique_words:
unique_words[word] += 1
else:
unique_words[word] = 1
In unique_words, the keys are words and the values are their frequencies. We can use the values function to get the values from the dictionary. The result has the type dict_values:
freqs = unique_words.values()
type(freqs)
dict_values
Before we plot them, we have to sort them, but the sort function doesn’t work with dict_values.
%%expect AttributeError
freqs.sort()
AttributeError: 'dict_values' object has no attribute 'sort'
And now we can use sort. By default it sorts in ascending order, but we can pass a keyword argument to reverse the order.
freq_list.sort(reverse=True)
Now, for the ranks, we need a sequence that counts from 1 to n, where n is the number of elements in freq_list. We can use the range function, which returns a value with type range. As a small example, here’s the range from 1 to 5.
range(1, 5)
range(1, 5)
However, there’s a catch. If we use the range to make a list, we see that “the range from 1 to 5” includes 1, but it doesn’t include 5.
list(range(1, 5))
[1, 2, 3, 4]
That might seem strange, but it is often more convenient to use range when it is defined this way, rather than what might seem like the more natural way. Anyway, we can get what we want by increasing the second argument by one:
list(range(1, 6))
[1, 2, 3, 4, 5]
So, finally, we can make a range that represents the ranks from 1 to n:
n = len(freq_list)
ranks = range(1, n+1)
ranks
range(1, 20484)
And now we can plot the frequencies versus the ranks:
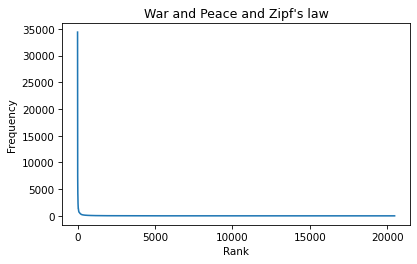
plt.plot(ranks, freq_list)
plt.xlabel('Rank') plt.ylabel('Frequency') plt.title("War and Peace and Zipf's law");
According to Zipf’s law, these frequencies should be inversely proportional to the ranks. If that’s true, we can write:
f = k / r
where r is the rank of a word, f is its frequency, and k is an unknown constant of proportionality. If we take the logarithm of both sides, we get
log f = log k – log r
This equation implies that if we plot f versus r on a log-log scale, we expect to see a straight line with intercept at log k and slope -1.
6.6. Logarithmic Scales
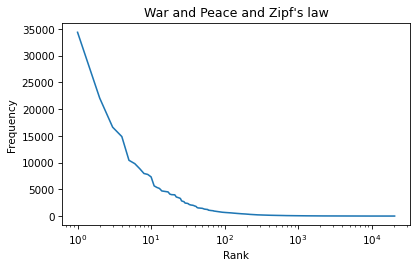
We can use plt.xscale to plot the x-axis on a log scale.
plt.plot(ranks, freq_list)
plt.xlabel('Rank')
plt.ylabel('Frequency')
plt.title("War and Peace and Zipf's law")
plt.xscale('log')
And plt.yscale to plot the y-axis on a log scale.
plt.plot(ranks, freq_list)
plt.xlabel('Rank')
plt.ylabel('Frequency')
plt.title("War and Peace and Zipf's law")
plt.xscale('log')
plt.yscale('log')
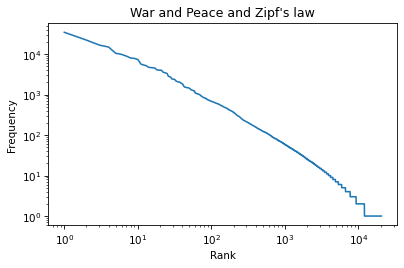
The result is not quite a straight line, but it is close. We can get a sense of the slope by connecting the end points with a line. First, we’ll select the first and last elements from xs.
xs = ranks[0], ranks[-1]
xs
(1, 20483)
And the first and last elements from ys.
ys = freq_list[0], freq_list[-1]
ys
(34389, 1)
And plot a line between them.
plt.plot(xs, ys, color='gray')
plt.plot(ranks, freq_list)
plt.xlabel('Rank')
plt.ylabel('Frequency')
plt.title("War and Peace and Zipf's law")
plt.xscale('log')
plt.yscale('log')
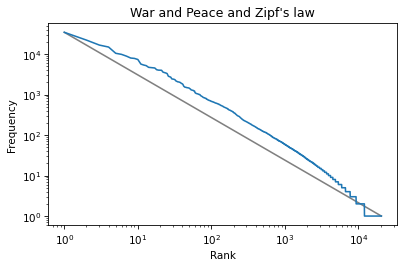
The slope of this line is the “rise over run”, that is, the difference on the y-axis divided by the difference on the x-axis. We can compute the rise using np.log10 to compute the log base 10 of the first and last values:
np.log10(ys)
array([4.53641955, 0. ])
Then we can use np.diff to compute the difference between the elements:
rise = np.diff(np.log10(ys))
rise
array([-4.53641955])
Exercise: Use log10 and diff to compute the run, that is, the difference on the x-axis. Then divide the rise by the run to get the slope of the grey line. Is it close to -1, as Zipf’s law predicts? Hint: yes.
I am excited to announce that I have started work on a third edition of Think Stats, to be published by O’Reilly Media in 2025. At this point the content is mostly settled, and I am revising chapters to get them ready for technical review.
For the third edition, I started by moving the book into Jupyter notebooks. This change has one immediate benefit – you can read the text, run the code, and work on the exercises all in one place. And the notebooks are designed to work on Google Colab, so you can get started without installing anything.
The move to notebooks has another benefit – the code is more visible. In the first two editions, some of the code was in the book and some was in supporting files available online. In retrospect, it’s clear that splitting the material in this way was not ideal, and it made the code more complicated than it needed to be. In the third edition, I was able to simplify the code and make it more readable.
Since the last edition was published, I’ve developed a library called empiricaldist that provides objects that represent statistical distributions. This library is more mature now, so the updated code makes better use of it.
When I started this project, NumPy and SciPy were not as widely used, and Pandas even less, so the original code used Python data structures like lists and dictionaries. This edition uses arrays and Pandas structures extensively, and makes more use of functions these libraries provide. I assume readers have some familiarity with these tools, but I explain each feature when it first appears.
The third edition covers the same topics as the original, in almost the same order, but the text is substantially revised. Some of the examples are new; others are updated with new data. I’ve developed new exercises, revised some of the old ones, and removed a few. I think the updated exercises are better connected to the examples, and more interesting.
Since the first edition, this book has been based on the thesis that many ideas that are hard to explain with math are easier to explain with code. In this edition, I have doubled down on this idea, to the point where there is almost no mathematical notation, only code.
Overall, I think these changes make Think Stats a better book. To give you a taste, here’s an excerpt from Chapter 12: Time Series Analysis.
Multiplicative Model
The additive model we used in the previous section is based on the assumption that the time series is well modeled as the sum of a long-term trend, a seasonal component, and a residual component – which implies that the magnitude of the seasonal component and the residuals does not vary over time.
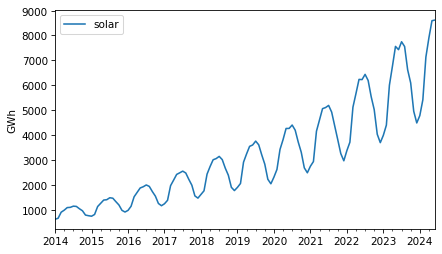
As an example that violates this assumption, let’s look at small-scale solar electricity production since 2014.
solar = elec["United States : small-scale solar photovoltaic"].dropna()
solar.plot(label="solar")
decorate(ylabel="GWh")
Over this interval, total production has increased several times over. And it’s clear that the magnitude of seasonal variation has increased as well.
If suppose that the magnitudes of seasonal and random variation are proportional to the magnitude of the trend, that suggests an alternative to the additive model in which the time series is the product of a trend, a seasonal component, and a residual component.
To try out this multiplicative model, we’ll split this series into training and test sets.
training, test = split_series(solar)
And call seasonal_decompose with the model=multiplicative argument.
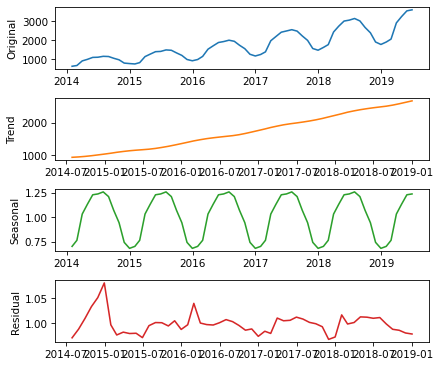
Now the seasonal and residual components are multiplicative factors. So, it looks like the seasonal component varies from about 25% below the trend to 25% above. And the residual component is usually less than 5% either way, with the exception of some larger factors in the first period.
The production of a solar panel is almost entirely a function of the sunlight it’s exposed to, so it makes sense that it follows an annual cycle so closely.
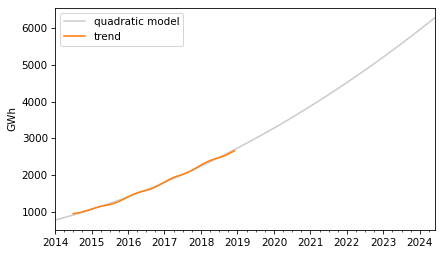
To predict the long term trend, we’ll use a quadratic model.
In the Patsy formula, the term "I(months**2)" adds a quadratic term to the model, so we don’t have to compute it explicitly. Here are the results.
display_summary(results)
coef
std err
t
P>|t|
[0.025
0.975]
Intercept
766.1962
13.494
56.782
0.000
739.106
793.286
months
22.2153
0.938
23.673
0.000
20.331
24.099
I(months ** 2)
0.1762
0.014
12.480
0.000
0.148
0.205
R-squared:
0.9983
The p-values of the linear and quadratic terms are very low, which suggests that the quadratic model captures more information about the trend than a linear model would – and the R² value is very high.
Now we can use the model to compute the expected value of the trend for the past and future.
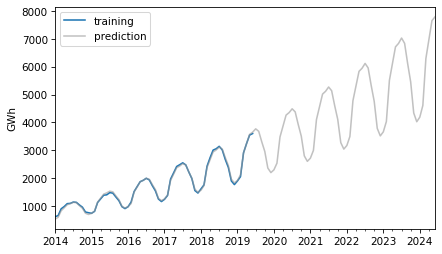
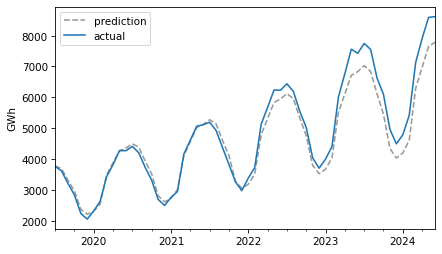
The retrodictions fit the training data well and the predictions seem plausible – now let’s see if they turned out to be accurate. Here are the predictions along with the test data.
For the first three years, the predictions are very good. After that, it looks like actual growth exceeded expectations.
In this example, seasonal decomposition worked well for modeling and predicting solar production, but in the previous example, it was not very effective for nuclear production. In the next section, we’ll try a different approach, autoregression.
How do I use bootstrapping to generate confidence intervals for a proportion/ratio? The situation is this:
I obtain samples of text with differing numbers of lines. From several tens to over a million. I have no control over how many lines there are in any given sample. Each line of each sample may or may not contain a string S. Counting lines according to S presence or S absence generates a ratio of S to S’ for that sample. I want to use bootstrapping to calculate confidence intervals for the found ratio (which of course will vary with sample size).
To do this I could either:
A. Literally resample (10,000 times) of size (say) 1,000 from the original sample (with replacement) then categorise S (and S’), and then calculate the ratio for each resample, and finally identify highest and lowest 2.5% (for 95% CI), or
B. Generate 10,000 samples of 1,000 random numbers between 0 and 1, scoring each stochastically as above or below original sample ratio (equivalent to S or S’). Then calculate CI as in A.
Programmatically A is slow and B is very fast. Is there anything wrong with doing B? The confidence intervals generated by each are almost identical.
The answer to the immediate question is that A and B are equivalent, so there’s nothing wrong with B. But in follow-up responses, a few related questions were raised:
Is resampling a good choice for this problem?
What size should the resamplings be?
How many resamplings do we need?
I don’t think resampling is really necessary here, and I’ll show some alternatives. And I’ll answer the other questions along the way.
I’ll download a utilities module with some of my frequently-used functions, and then import the usual libraries.
Pallor and Probability
As an example, let’s use one of the exercises from Think Python:
The Count of Monte Cristo is a novel by Alexandre Dumas that is considered a classic. Nevertheless, in the introduction of an English translation of the book, the writer Umberto Eco confesses that he found the book to be “one of the most badly written novels of all time”.
In particular, he says it is “shameless in its repetition of the same adjective,” and mentions in particular the number of times “its characters either shudder or turn pale.”
To see whether his objection is valid, let’s count the number number of lines that contain the word pale in any form, including pale, pales, paled, and paleness, as well as the related word pallor. Use a single regular expression that matches all of these words and no others.
The following cell downloads the text of the book from Project Gutenberg.
def clean_file(input_file, output_file):
reader = open(input_file)
writer = open(output_file, 'w')
for line in reader:
if is_special_line(line):
break
for line in reader:
if is_special_line(line):
break
writer.write(line)
reader.close()
writer.close()
clean_file('pg1184.txt', 'pg1184_cleaned.txt')
And we’ll use the following function to count the number of lines that contain a particular pattern of characters.
import re
def count_matches(lines, pattern):
count = 0
for line in lines:
result = re.search(pattern, line)
if result:
count += 1
return count
readlines reads the file and creates a list of strings, one for each line.
lines = open('pg1184_cleaned.txt').readlines()
n = len(lines)
n
61310
There are about 61,000 lines in the file.
The following pattern matches “pale” and several related words.
pattern = r'\b(pale|pales|paled|paleness|pallor)\b'
k = count_matches(lines, pattern)
k
223
These words appear in 223 lines of the file.
p_est = k / n
p_est
0.0036372533028869677
So the estimated proportion is about 0.0036. To quantify the precision of that estimate, we’ll compute a confidence interval.
Resampling
First we’ll use the method OP called A – literally resampling the lines of the file. The following function takes a list of lines and selects a sample, with replacement, that has the same size.
In a resampled list, the same line can appear more than once, and some lines might not appear at all. So in any resampling, the forbidden words might appear more times than in the original text, or fewer. Here’s an example.
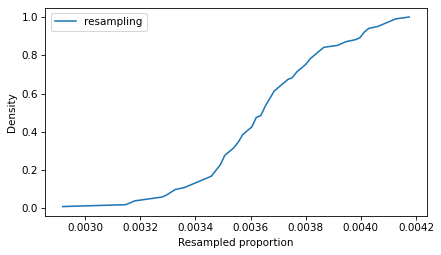
In this resampling, the words appear in 201 lines, fewer than in the original (223).
If we repeat this process many times, we can compute a sample of possible values of k. Because this method is slow, we’ll only repeat it 101 times.
ks_resampling = [count_matches(resample(lines), pattern) for i in range(101)]
With these different values of k, we can divide by n to get the corresponding values of p.
ps_resampling = np.array(ks_resampling) / n
To see what the distribution of those values looks like, we’ll plot the CDF.
from empiricaldist import Cdf
Cdf.from_seq(ps_resampling).plot(label='resampling')
decorate(xlabel='Resampled proportion', ylabel='Density')
So that’s the slow way to compute the sampling distribution of the proportion. The method OP calls B is to simulate a Bernoulli trial with size n and probability of success p_est. One way to do that is to draw random numbers from 0 to 1 and count how many are less than p_est.
(np.random.random(n) < p_est).sum()
229
Equivalently, we can draw a sample from a Bernoulli distribution and add it up.
from scipy.stats import bernoulli
bernoulli(p_est).rvs(n).sum()
232
These values follow a binomial distribution with parameters n and p_est. So we can simulate a large number of trials quickly by drawing values from a binomial distribution.
from scipy.stats import binom
ks_binom = binom(n, p_est).rvs(10001)
Dividing by n, we can compute the corresponding sample of proportions.
ps_binom = np.array(ks_binom) / n
Because this method is so much faster, we can generate a large number of values, which means we get a more precise picture of the sampling distribution.
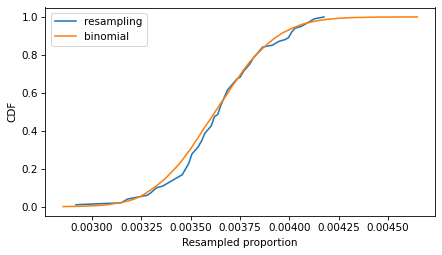
The following figure compares the CDFs of the values we got by resampling and the values we got from the binomial distribution.
If we run the resampling method longer, these CDFs converge, so the two methods are equivalent.
To compute a 90% confidence interval, we can use the values we sampled from the binomial distribution.
np.percentile(ps_binom, [5, 95])
array([0.0032458 , 0.00404502])
Or we can use the inverse CDF of the binomial distribution, which is even faster than drawing a sample. And it’s deterministic – that is, we get the same result every time, with no randomness.
binom(n, p_est).ppf([0.05, 0.95]) / n
array([0.0032458 , 0.00404502])
Using the inverse CDF of the binomial distribution is a good way to compute confidence intervals. But before we get to that, let’s see how resampling behaves as we increase the sample size and the number of iterations.
Sample Size
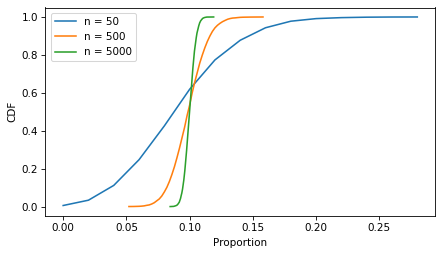
In the example, the sample size is more than 60,000, so the CI is very small. The following figure shows what it looks like for more moderate sample sizes, using p=0.1 as an example.
p = 0.1
ns = [50, 500, 5000]
ci_df = pd.DataFrame(index=ns, columns=['low', 'high'])
for n in ns:
ks = binom(n, p).rvs(10001)
ps = ks / n
Cdf.from_seq(ps).plot(label=f"n = {n}")
ci_df.loc[n] = np.percentile(ps, [5, 95])
decorate(xlabel='Proportion', ylabel='CDF')
As the sample size increases, the spread of the sampling distribution gets smaller, and so does the width of the confidence interval.
With resampling methods, it is important to draw samples with the same size as the original dataset – otherwise the result is wrong.
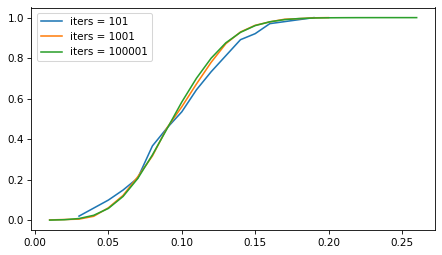
But the number of iterations doesn’t matter as much. The following figure shows the sampling distribution if we run the sampling process 101, 1001, and 10,001 times.
p = 0.1
n = 100
iter_seq = [101, 1001, 100001]
for iters in iter_seq:
ks = binom(n, p).rvs(iters)
ps = ks / n
Cdf.from_seq(ps).plot(label=f"iters = {iters}")
decorate()
The sampling distribution is the same, regardless of how many iterations we run. But with more iterations, we get a better picture of the distribution and a more precise estimate of the confidence interval. For most problems, 1001 iterations is enough, but if you can generate larger samples fast enough, more is better.
However, for this problem, resampling isn’t really necessary. As we’ve seen, we can use the binomial distribution to compute a CI without drawing a random sample at all. And for this problem, there are approximations that are even easier to compute – although they come with some caveats.
Approximations
If n is large and p is not too close to 0 or 1, the sampling distribution of a proportion is well modeled by a normal distribution, and we can approximate a confidence interval with just a few calculations.
For a given confidence level, we can use the inverse CDF of the normal distribution to compute a
score, which is the number of standard deviations the CI should span – above and below the observed value of p – in order to include the given confidence.
from scipy.stats import norm
confidence = 0.9
z = norm.ppf(1 - (1 - confidence) / 2)
z
1.6448536269514722
A 90% confidence interval spans about 1.64 standard deviations.
Now we can use the following function, which uses p, n, and this z score to compute the confidence interval.
def confidence_interval_normal_approx(k, n, z):
p = k / n
margin_of_error = z * np.sqrt(p * (1 - p) / n)
lower_bound = p - margin_of_error
upper_bound = p + margin_of_error
return lower_bound, upper_bound
To test it, we’ll compute n and k for the example again.
n = len(lines)
k = count_matches(lines, pattern)
n, k
(61310, 223)
Here’s the confidence interval based on the normal approximation.
ci_normal = confidence_interval_normal_approx(k, n, z)
ci_normal
(0.003237348046298746, 0.00403715855947519)
In the example, n is large, which is good for the normal approximation, but p is small, which is bad. So it’s not obvious whether we can trust the approximation.
An alternative that’s more robust is the Wilson score interval, which is reliable for values of p close to 0 and 1, and sample sizes bigger than about 5.
def confidence_interval_wilson_score(k, n, z):
p = k / n
factor = z**2 / n
denominator = 1 + factor
center = p + factor / 2
half_width = z * np.sqrt((p * (1 - p) + factor / 4) / n)
lower_bound = (center - half_width) / denominator
upper_bound = (center + half_width) / denominator
return lower_bound, upper_bound
Here’s the 90% CI based on Wilson scores.
ci_wilson = confidence_interval_wilson_score(k, n, z)
ci_wilson
(0.003258660468175958, 0.00405965209814987)
Another option is the Clopper-Pearson interval, which is what we computed earlier with the inverse CDF of the binomial distribution. Here’s a function that computes it.
from scipy.stats import binom
def confidence_interval_exact_binomial(k, n, confidence=0.9):
alpha = 1 - confidence
p = k / n
lower_bound = binom.ppf(alpha / 2, n, p) / n if k > 0 else 0
upper_bound = binom.ppf(1 - alpha / 2, n, p) / n if k < n else 1
return lower_bound, upper_bound
A final alternative is the Jeffreys interval, which is derived from Bayes’s Theorem. If we start with a Jeffreys prior and observe k successes out of n attempts, the posterior distribution of p is a beta distribution with parameters a = k + 1/2 and b = n - k + 1/2. So we can use the inverse CDF of the beta distribution to compute a CI.
from scipy.stats import beta
def bayesian_confidence_interval_beta(k, n, confidence=0.9):
alpha = 1 - confidence
a, b = k + 1/2, n - k + 1/2
lower_bound = beta.ppf(alpha / 2, a, b)
upper_bound = beta.ppf(1 - alpha / 2, a, b)
return lower_bound, upper_bound
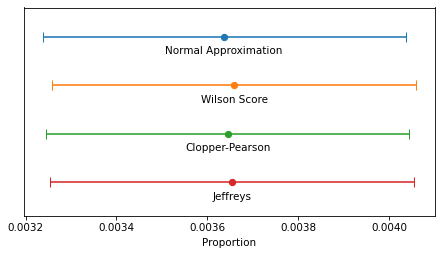
In this example, because n is so large, the intervals are all similar – the differences are too small to matter in practice. For smaller values of n, the normal approximation becomes unreliable, and for very small values, none of them are reliable.
The normal approximation and Wilson score interval are easy and fast to compute. On my old laptop, they take 1-2 microseconds.
%timeit confidence_interval_normal_approx(k, n, z)
1.04 µs ± 4.04 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
%timeit confidence_interval_wilson_score(k, n, z)
1.64 µs ± 28.6 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
Evaluating the inverse CDF of the binomial and beta distributions are more complex computations – they take about 100 times longer.
%timeit confidence_interval_exact_binomial(k, n)
195 µs ± 7.53 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%timeit bayesian_confidence_interval_beta(k, n)
269 µs ± 4.6 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
But they still take less than 300 microseconds, so unless you need to compute millions of confidence intervals per second, the difference in computation time doesn’t matter.
Discussion
If you took a statistics class and learned one of these methods, you probably learned the normal approximation. That’s because it is easy to explain and, because it is based on a form of the Central Limit Theorem, it helps to justify time spent learning about the CLT. But in my opinion it should never be used in practice because it is dominated by the Wilson score interval – that is, it is worse than Wilson in at least one way and better in none.
I think the Clopper-Pearson interval is equally easy to explain, but when n is small, there are few possible values of k, and therefore few possible values of p – and the interval can be wider than it needs to be.
The Jeffreys interval is based on Bayesian statistics, so it takes a little more explaining, but it behaves well for all values of n and p. And when n is small, it can be extended to take advantage of background information about likely values of p.
For these reasons, the Jeffreys interval is my usual choice, but in a computational environment that doesn’t provide the inverse CDF of the beta distribution, I would use a Wilson score interval.
OP is working in LiveCode, which doesn’t provide a lot of math and statistics libraries, so Wilson might be a good choice. Here’s a LiveCode implementation generated by ChatGPT.
-- Function to calculate the z-score for a 95% confidence level (z ≈ 1.96)
function zScore
return 1.96
end zScore
-- Function to calculate the Wilson Score Interval with distinct bounds
function wilsonScoreInterval k n
-- Calculate proportion of successes
put k / n into p
put zScore() into z
-- Common term for the interval calculation
put (z^2 / n) into factor
put (p + factor / 2) / (1 + factor) into adjustedCenter
-- Asymmetric bounds
put sqrt(p * (1 - p) / n + factor / 4) into sqrtTerm
-- Lower bound calculation
put adjustedCenter - (z * sqrtTerm / (1 + factor)) into lowerBound
-- Upper bound calculation
put adjustedCenter + (z * sqrtTerm / (1 + factor)) into upperBound
return lowerBound & comma & upperBound
end wilsonScoreInterval
In a previous article, I looked at 93 measurements from the ANSUR-II dataset and found that ear protrusion is not correlated with any other measurement. In a followup article, I used principle component analysis to explore the correlation structure of the measurements, and found that once you have exhausted the information encoded in the most obvious measurements, the ear-related measurements are left standing alone.
I have a conjecture about why ears are weird: ear growth might depend on idiosyncratic details of the developmental environment — so they might be like fingerprints. Recently I discovered a hint that supports my conjecture.
This Veritasium video explains how we locate the source of a sound.
In general, we use small differences between what we hear in each ear — specifically, differences in amplitude, quality, time delay, and phase. That works well if the source of the sound is to the left or right, but not if it’s directly in front, above, or behind — anywhere on vertical plane through the centerline of your head — because in those cases, the paths from the source to the two ears are symmetric.
Fortunately we have another trick that helps in this case. The shape of the outer ear changes the quality of the sound, depending on the direction of the source. The resulting spectral cues makes it possible to locate sources even when they are on the central plane.
The video mentions that owls have asymmetric ears that make this trick particularly effective. Human ears are not as distinctly asymmetric as owl ears, but they are not identical.
And now, based on the Veritasium video, I suspect that might be a feature — the shape of the outer ear might be unpredictably variable because it’s advantageous for our ears to be asymmetric. Almost everything about the way our bodies grow is programmed to be as symmetric as possible, but ears might be programmed to be different.
An article in a recent issue of The Economist suggests, right in the title, “Investors should avoid a new generation of rip-off ETFs”. An ETF is an exchange-traded fund, which holds a collection of assets and trades on an exchange like a single stock. For example, the SPDR S&P 500 ETF Trust (SPY) tracks the S&P 500 index, but unlike traditional index funds, you can buy or sell shares in minutes.
There’s nothing obviously wrong with that – but as an example of a “rip-off ETF”, the article describes “defined-outcome funds” or buffer ETFs, which “offer investors an enviable-sounding opportunity: hold stocks, with protection against falling prices. All they must do is forgo annual returns above a certain level, often 10% or so.”
That might sound good, but the article explains, “Over the long term, they are a terrible deal for investors. Much of the compounding effect of stock ownership comes from rallies.”
To demonstrate, they use the value of the S&P index since 1980: “An investor with returns capped at 10% and protected from losses would have made a real return of 403% over the period, a fraction of the 3,155% return offered by just buying and holding the S&P 500.”
So that sounds bad, but returns from 1980 to the present have been historically unusual. To get a sense of whether buffer ETFs are more generally a bad deal, let’s get a bigger picture.
The MeasuringWorth Foundation has compiled the value of the Dow Jones Industrial Average at the end of each day from February 16, 1885 to the present, with adjustments at several points to make the values comparable. The series I collected starts on February 16, 1885 and ends on August 30, 2024. The following cells download and read the data.
To compute annual returns, we’ll start by selecting the closing price on the last trading day of each year (dropping 2024 because we don’t have a complete year).
Looking at the years with the biggest losses and gains, we can see that most of the extremes were before the 1960s – with the exception of the 2008 financial crisis.
annual.dropna().sort_values(by='Return')
DJIA
Ratio
Return
Date
1931
77.9000
0.473326
-52.667396
1907
43.0382
0.622683
-37.731743
2008
8776.3900
0.661629
-33.837097
1930
164.5800
0.662347
-33.765293
1920
71.9500
0.670988
-32.901240
…
…
…
…
1954
404.3900
1.439623
43.962264
1908
63.1104
1.466381
46.638103
1928
300.0000
1.482213
48.221344
1933
99.9000
1.666945
66.694477
1915
99.1500
1.816599
81.659949
138 rows × 3 columns
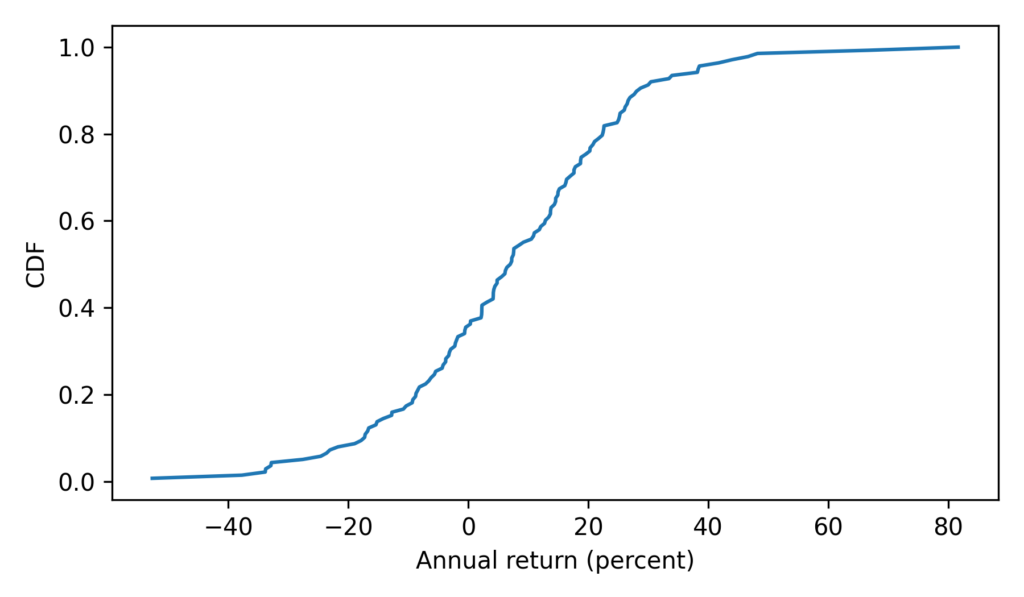
Here’s what the distribution of annual returns looks like.
With this function, we can replicate the analysis The Economist did with the S&P 500. Here are the results for the DJIA from the beginning of 1980 to the end of 2023.
A buffer ETF over this period would have grown by a factor of more than 15 in nominal dollars, with no risk of loss. But an index fund would have grown by a factor of almost 45. So yeah, the ETF would have been a bad deal.
However, if we go back to the bad old days, an investor in 1900 would have been substantially better off with a buffer ETF held for 43 years – a factor of 7.2 compared to a factor of 2.8.
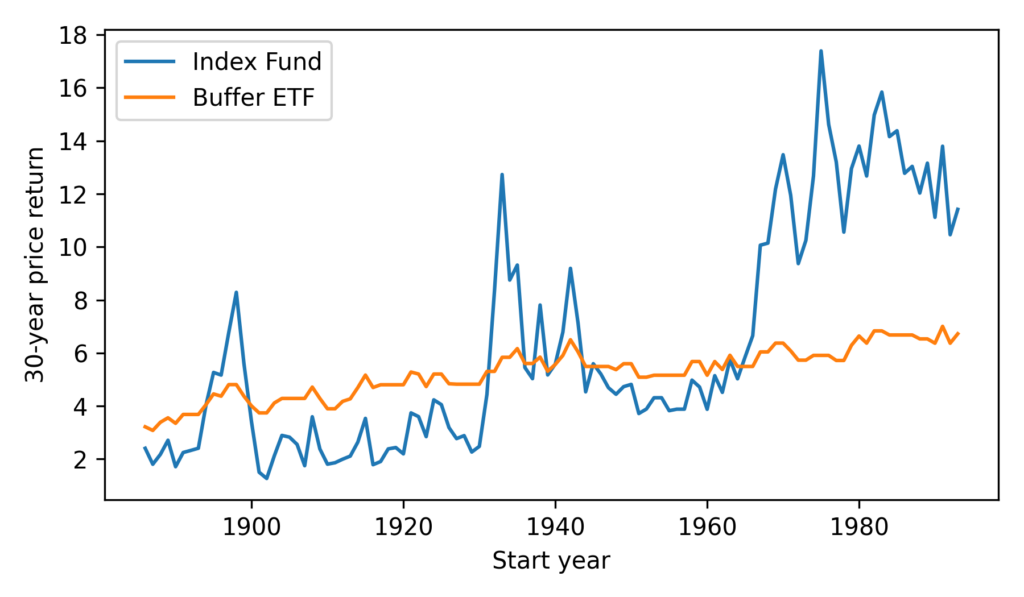
It seems we can cherry-pick the data to make the comparison go either way – so let’s see how things look more generally. Starting in 1886, we’ll compute price returns for all 30-year intervals, ending with the interval from 1993 to 2023.
The buffer ETF performs as advertised, substantially reducing volatility. But it has only occasionally been a good deal, and not in my lifetime.
According to ChatGPT, the primary reasons for strong growth in stock prices since the 1960s are “technological advancements, globalization, financial market innovation, and favorable monetary policies”. If you think these elements will generally persist over the next 30 years, you might want to avoid buffer ETFs.
For people at the conference who don’t know me, this might be a good time to introduce you to this blog, where I write about data science and Bayesian statistics, and to Probably Overthinking It, the book based on the blog, which was published by University of Chicago Press last December. Here’s an outline of the book with links to excerpts I’ve published in the blog and talks I’ve presented based on some of the chapters.
For your very own copy, you can order from Bookshop.org if you want to support independent bookstores, or Amazon if you don’t.
Chapter 2 is about the inspection paradox, which affects our perception of many real-world scenarios, including fun examples like class sizes and relay races, and more serious examples like our understanding of criminal justice and ability to track infectious disease. I published a prototype of this chapter as an article called “The Inspection Paradox is Everywhere“, and gave a talk about it at PyData NYC:
Chapter 3 presents three consequences of the inspection paradox in demography, especially changes in fertility in the United States over the last 50 years. It explains Preston’s paradox, named after the demographer who discovered it: if each woman has the same number of children as her mother, family sizes — and population — grow quickly; in order to maintain constant family sizes, women must have fewer children than their mothers, on average. I published an excerpt from this chapter, and it was discussed on Hacker News.
Chapter 4 is about extremes, outliers, and GOATs (greatest of all time), and two reasons the distribution of many abilities tends toward a lognormal distribution: proportional gain and weakest link effects. I gave a talk about this chapter for PyData Global 2023:
Chapter 5 is about the surprising conditions where something used is better than something new. Most things wear out over time, but sometimes longevity implies information, which implies even greater longevity. This property has implications for life expectancy and the possibility of much longer life spans. I gave a talk about this chapter at ODSC East 2024 — there’s no recording, but the slides are here.
Chapter 6 introduces Berkson’s paradox — a form of collision bias — with some simple examples like the correlation of test scores and some more important examples like COVID and depression. Chapter 7 uses collision bias to explain the low birthweight paradox and other confusing results from epidemiology. I gave a “Talk at Google” about these chapters:
Chapter 8 shows that the magnitudes of natural and human-caused disasters follow long-tailed distributions that violate our intuition, defy prediction, and leave us unprepared. Examples include earthquakes, solar flares, asteroid impacts, and stock market crashes. I gave a talk about this chapter at SciPy 2023:
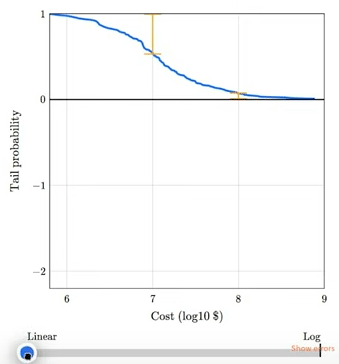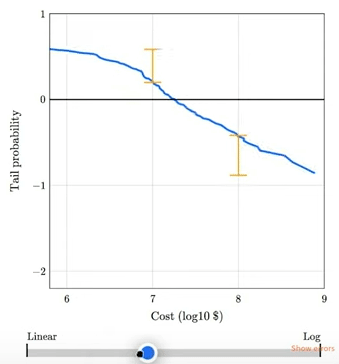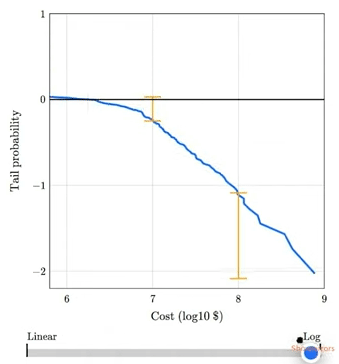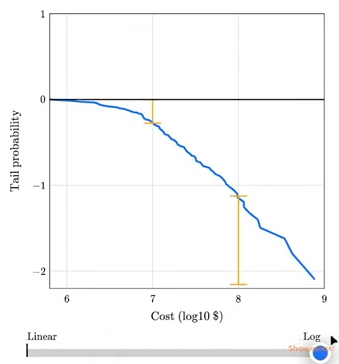
The talk includes this animation showing how plotting a tail distribution on a log-y scale provides a clearer picture of the extreme tail behavior.
Chapter 9 is about the base rate fallacy, which is the cause of many statistical errors, including misinterpretations of medical tests, field sobriety tests, and COVID statistics. It includes a discussion of the COMPAS system for predicting criminal behavior.
Chapter 10 is about Simpson’s paradox, with examples from ecology, sociology, and economics. It is the key to understanding one of the most notorious examples of misinterpretation of COVID data. This is the first of three chapters that use data from the General Social Survey (GSS).
Chapter 12 is about the Overton Paradox, a name I’ve given to a pattern observed in GSS data: as people get older, their beliefs become more liberal, on average, but they are more likely to say they are conservative. This chapter is the basis of this interactive lesson at Brilliant.org. And I gave a talk about it at PyData NYC 2022:
There are still a few chapters I haven’t given a talk about, so watch this space!
Again, you can order the book from Bookshop.org if you want to support independent bookstores, or Amazon if you don’t.
Supporting code for the book is in this GitHub repository. All of the chapters are available as Jupyter notebooks that run in Colab, so you can replicate my analysis. If you are teaching a data science or statistic class, they make good teaching examples.