So far we have been cheating by using the trace data to estimate the distribution parameters, and then using the estimated parameters as inputs to the prediction algorithm. Of course, a real system would not have the luxury of knowing ahead of time the exact distribution of lifetimes of the jobs that would be submitted.
Assuming that the distributions do not change drastically over time, though, it should be possible to make accurate predictions using parameters estimated from recent accounting data. To test this claim, we divided our trace data into four intervals, each four months long. For each interval we found the distribution of lifetimes (broken down by queue name, as in Section 3.1) and estimated the parameters of each distribution.
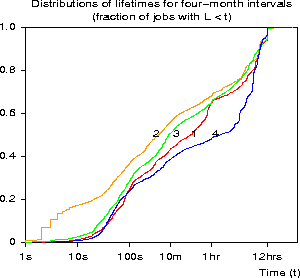
Figure 8: The distribution of lifetimes on the Intel Paragon at SDSC during four four-month intervals from January 1, 1995 to May 1, 1996.
Figure 8 shows the distribution of lifetimes for each interval. It is clear that this distribution changes over time, and that for the last year there has been a trend toward longer run times. Hotovy et al. [11] report a similar trend on the IBM SP2 at CTC -- these trends may indicate a maturing workload as users submit fewer test runs and more production runs.
Table 5 shows the median lifetime of jobs submitted to each
queue (in seconds). The lifetimes of sequential jobs have been
consistent over time, but short jobs have been getting shorter, and
both medium and long jobs have been getting longer.
lifetime of jobs submitted to each
queue (in seconds). The lifetimes of sequential jobs have been
consistent over time, but short jobs have been getting shorter, and
both medium and long jobs have been getting longer.
Table 5

To evaluate the impact of obsolete parameters on the accuracy of our predictors, we simulated the last three trace intervals (May '95 through April '96) using, in each interval, the parameters estimated during the previous interval. We feel that this is a realistic simulation of a system that updates its parameters every four months based on accounting data from the previous four months.
In general, the performance of the predictors is not as good as with the optimistically accurate parameters we have been using: CC for Predictor A is 0.60 (down from 0.63), for Predictor B is 0.57 (down from 0.61), and for the combined predictor is 0.62 (down from 0.65). But the difference in accuracy is not large, suggesting that the predictors are not greatly impaired if the parameters are obsolete. Thus, we expect that in a practical system it would be sufficient to estimate new parameters only occasionally (maybe monthly).
In this workload, the distribution of lifetimes for medium and long jobs is becoming increasingly bimodal (similar to Figure 6). This indicates that there are actually two classes of jobs in these queues, and that users are failing to distinguish between them when they choose a queue. As the quality of information provided by users declines, we find that our predictions become less accurate. We can mitigate this effect in part by using additional information about jobs to create more classes. For example, we found that both cluster size and requested memory size are correlated with run time. We could create a set of classes that is the cross product of the sets of attributes; the only limit on the number of classes is that we need enough jobs in each class to get a good estimate of the class' distribution.
Another way to improve the information content of the distributions is to change the interface to the queueing system to provide better feedback about the run times of users' jobs and thereby solicit better estimates.